







Hive Reviews & Product Details
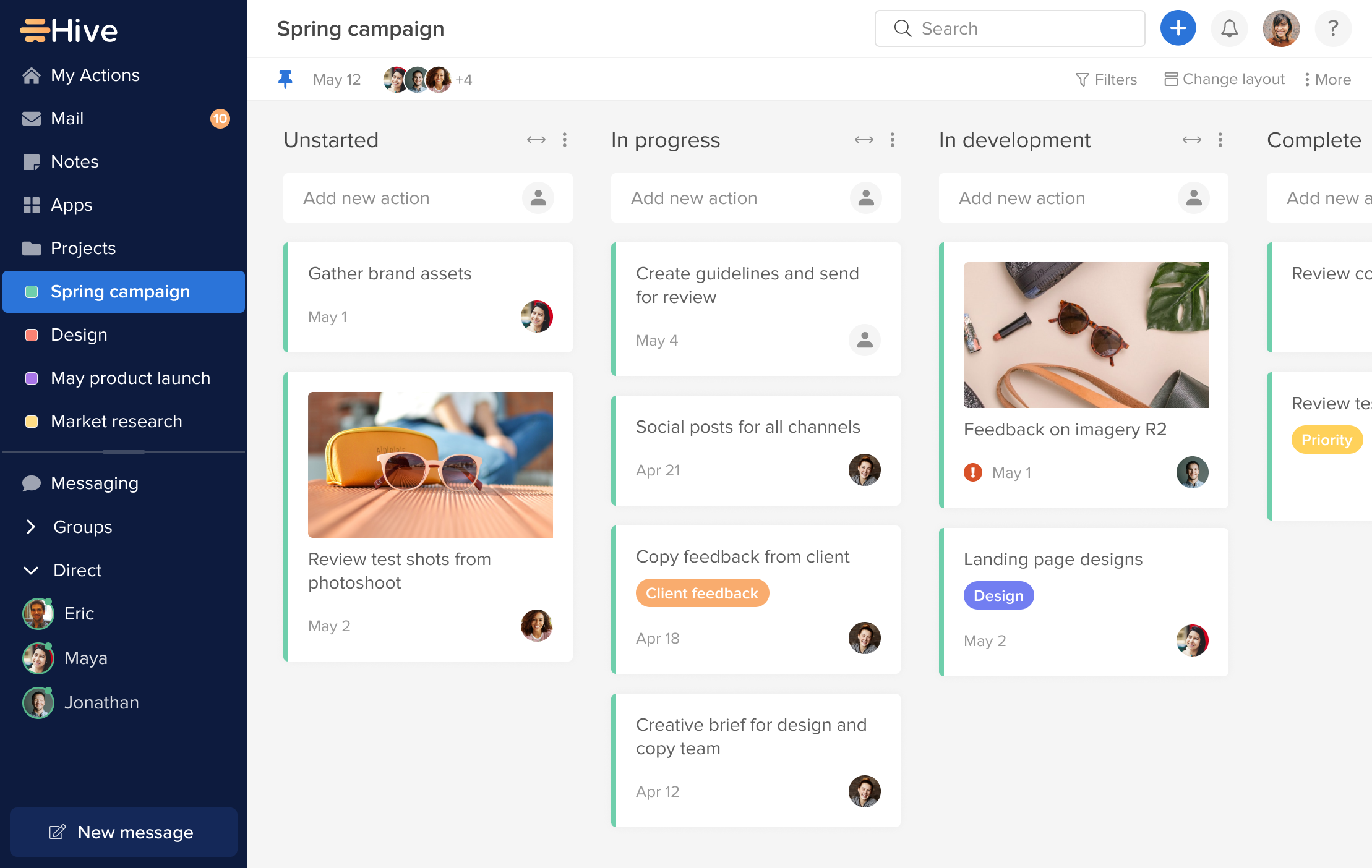
Hive is an all-in-one project management tool developed to “help teams move faster” regardless of how they work. Features are created based on users’ requests and are updated weekly, making Hive the world’s first democratic software platform. It’s best known for its capabilities in project management, time management, team collaboration, automation, and an array of integrations with third-party software. Hive is free to use for solo users and with premium versions available to teams and enterprises.



| Capabilities |
|
|---|---|
| Segment |
|
| Deployment | Cloud / SaaS / Web-Based, Mobile Android, Mobile iPad, Mobile iPhone |
| Support | 24/7 (Live rep), Chat, Email/Help Desk, FAQs/Forum, Knowledge Base, Phone Support |
| Training | Documentation |
| Languages | English |




Fantastic and attractive UI Straightforward when it comes to tracking,assigning and monitoring projects Hive helps me keep track of all our projects and people connected to these projects
I don't have anything yet to state as a dislike I am satisfied in using hive
Managing the projects and getting the time logs

Hive is the best Datawarehouse and open source. Easy to use. It has a query language HiveQL. The syntax is same as SQL. So it is easy to write the hive queries and easy to get reports and business insights. Best Olfor analytics. And easily integrated with Spark, Hadoop and cloud also.
Higher latency is the drawback. Developments should be made to improve the latency of the complex queries.
Helping us to get business insights and reporting. Helping us to analyse the data and draw some conclusions to improve the business.

Best thing about Hive is it alows us to write the code in sql for processing and managing the data. It allows us to partition and distribut the data among the cluster machines. We can also choose execution engine like spark, tez,mapredice while rinning in hive. If you your processing and analysing the bulk volume of batch data then hive is best.
It supports only structure data and we can't do updates too. Only supports OLAP.
We are managing our data warehouse for analytical purpose using hive. We used to partition and cluster the tables for better parallel processing and less shuffling so the processing will be optimised. We used to read the hive tables with spark too for better computation and speed.

Good querying on hive databases.and easy to create schemas
It does not allow datatypes conversion. As it will result in lost of data
Querying on hive dbs. Also hs2 and hive metastore resulting fast results
1) ability to handle PetaByte scale of data 2) ability to work with near SQL query language 3) schema on read capibility
1) optimizer technology is still maturing
1) handling huge datasets 2) handling semi-structured and structured data sets with the same tool
The SQL-like syntax makes it easy to use
Its reliance on mapreduce makes it sometimes very slow even for a simple task
Run specific queries on hadoop files
Hive is one of the Apache projects. it is a data warehouse software which facilitates querying and managing large datasets residing in distributed storage. It provides a way to enable easy data extract/transform/load (ETL) Some of the nice features include (1) a simple SQL-like query language, called HiveQL, that enables users familiar with SQL to query the data. But it is a bit different from SQL standard. For example, HiveQL can also be extended with custom scalar functions (UDF's), aggregations (UDAF's), and table functions (UDTF's). (2) You can define your own read or written data format called Hive SerDe. (3) Hive can be run on Hadoop and HDFS. It has very good scalability. Personally speaking, I use hive mainly for ad hoc quires and reports. For BI reports Hive is the best since you can reuse all the SQL that you have done for traditional data warehouses. Also with Hive Server2 you get a real JDBC support so you can plug your BI tools to it. Many more SQL features like cubes, rollups, windowing, lag, lead, etc are being added to Hive through Hortonworks Stinger initiative. Hive also produces very compact code, which is always good for reading and debugging.
Too large code base. It is hard to maintain and support. And, there are too many configurations. If you take a look at the HiveConf.java, you will be confused with so many configurations there. It is easy to get lost when you configure them. And, if you configure some of them in a wrong way, you may suffer from bad query performance.
We are developing Hive. Hive is part of our product
Its exhilarating how well it seamlessly connects work, through its group messaging that spurs collaboration, its flexible project layouts, customer insights and reviews that help in strategy.
One thing to note is that its heavy on consumption and it requires enough ram to slow some integrated apps down. That's an issue that needs solving.
Its been using data analysis of the workflows to expose how work is actually being done, what's needed to optimize operations, how to schedule, allocate and much more. Its been a great help at getting everyone performing and moving as per timelines and objectives.
Hive offer tool's for project planning, including the ability for track project and timeline, create and assign tasks and manage resources.
I have no dislike towards hive since is the one I'm using
It allows users to analyse large amount structure and semi structure data
Hive is a very valuable tool as it provides wrappers for data analysis and querying on Big data for organizations with huge amounts of data to be processed. It is built on top of Hadoop and makes SQL query building and storing quite convenient!
The biggest disadvantage of using Hive is that it does not provide or offer real-time queries and especially for row level updates as the latency is quite high in Hive.
Hive solves the problem of big data processing and analysis for me and my company. We are able to process and analyze huge amounts of data with the help of capabilities provided by Hive. It also allows parallel processing which makes it quite fast to use.

File formats for optimizations, external
cannot analyse unstructured data, not much faster when it comes to complex operations on very huge data
adhoc analytics and batch analytics on big data

The data distribution and data processing in hive is very good in hive. DDL and DML functions in hive are better than conventional sql databases. Hive is better known for fault resistance.
The data output on hive is very slow. The data processing is very slow and the output is delayed due to this slow processing. Also the syntax is bit complex than conventional sql language.
Fault tolerance is very good feature which helps in data storing. Incase one database is lost, there isna backup created and this database can retrieved easily and intact.

the ease of use and its interface is best
running of queries in slow mode of map-reduced
storing the large data and retirving it through queries
Caso contrário, se você escrevê-lo como um SQL normal, pode levar horas para processar Mas é um pouco diferente do padrão SQL Pessoalmente falando, eu uso hive principalmente para ad hoc quires e relatórios é um software de armazenamento de dados que facilita a consulta e gerenciamento de grandes conjuntos de dados residindo em armazenamento distribuído
O ajuste de desempenho é difícil e torna-se difícil para consultas complexas, ele ainda tem alguns bugs, como todos os dados que vão para um único redutor, o que pode levar a retardar os resultados da consulta. -> Algumas das operações SQL não funcionam na colméia, como as associações de não igualdade, os dados não podem ser atualizados, mas teremos que reescrever
Estamos desenvolvendo o Hive Para pessoas que estão acostumadas a escrever consultas SQL, seria muito bom usar o Hive em cima do hadoop para arquivos armazenados no HDFS. Atividade do Dumping Site Dados de streaming de Big Data, bem como logs de dados no Hive Estamos desenvolvendo o Hive
Ease to get started. Leverages sql knowledge. Has reasonable documentation. Fast to write queries.
Documentation sparse in some areas such as datetime formats. Queries run slowly and often fail to complete.
Preprocessing for machine learning pipeline. Running ad hoc queries on customer databases to generate high level summaries.
Its very user friendly. Easy to install and use. I like the interface very much .
Nothing I can think of. I had a great experience working on HIVE and was satisfied with all the features as it met all my requirements.
I was working on a school project as a part of Big Data course and executing queries with HIVE made the whole project lot more simpler.
The syntax of hive! Its almost SQL so its easy to use. External tables, partitions, buckets, UDFs all the features I like to use with hive. ORC data format occupying lesser space and retrieving the data much faster. Learning curve looks easier as it is similar to SQL but hold on! you must learn all the features of hive before writing a big hql to join multiple hundreds GBs tables and fetch results. Otherwise if you write it like a regular SQL it may take hours to process. So hive is always at its best when you set the optimization parameters before you run your scripts. Also its complex datatypes make hive more useful than other RDBMS.
Hive is comparatively slower than its competitors. Its easy to use but that comes with the cost of processing, If you are using it just for batch processing then hive is well and fine.
Generating datasets from huge files for reporting purposes.
Hive provides an ease to the user who wants to store bulk data, in a tabular manner. It works on the same queries like SQL, making it easy for using the traditional database system. Because of this reason, people need not have to study some new language and can still adapt to the Big Data Culture. Also it has features like partition, and bucketing, helping in segregation of data. Data can directly be loaded into hive, by HDFS, using the CSV files of the same format, or from Hbase by making a pointer to the Hbase table, providing a link within Hadoop.
For small amount of data also, it runs map reduce job, which consumes some time, and thus is not efficient for the same. We do not have a concept of primary key in Hive, so we can have redundant entries. Also till the older version, update and delete were not possible, and now also in the new version, if we want to use the update and delete commands, the performance of the tool gets degraded.
We are using Hive for storing logs, of data, being generated, in our business. Further we will be using these logs for reconciliation purpose, helping in keeping a track of data.
The Hive is intended to simplify your experience with Hadoop and allows developers and business analyst apply their SQL knowledge to query data, build reports, build etl etc.
As the open source software it has common issues with support. Also Hive doesn't support many features that traditional SQL has.
The main purpouse of using Hive is to building reports and do analysis of data that is stored in the Hadoop file system. As for now it is the only one framework that can be used by all most popular BI tools to read the data from the HDFS.
Ease of use as well as ability to scale. It has proven its reliability. They have continued to add more features and increased its speed at the same time.
Speed is still slower compared to newer distributed warehouses. Also, it still uses mapreduce behind the scene which is very slow in the present days.
Storing large amount of data that could not fit in to any relational database system. Being able to derive valuable insight into our data by running mapreduce jobs on data stored in Hive.